


產品特色
- Ampere GPU 架構
- 10,240 NVIDIA® CUDA® 核心
- 320 NVIDIA® Tensor 核心
- 80 NVIDIA® RT 核心
- 24GB GDDR6 記憶體
- 高達 768GB/s記憶體頻寬
- 最大功耗: 230W
- 繪圖匯流排: PCI-E 4.0 x16
- 主動式散熱
- 支援 NVIDIA vGPU軟體
- 顯示介面: DP 1.4 (4)
- NVLink: 2槽位/3槽位低結構橋接器
特色與介紹
NVIDIA RTX™ A5500 釋放 NVIDIA Ampere 架構的強大功能,為專業人士提供全新等級的性能、功能和協作,激發他們進行無界限的創作。基於 NVIDIA Ampere 架構的第二代 NVIDIA RTX 技術使藝術家、設計師、工程師和科學家能夠通過增強的即時光線追踪、加速的 AI、高級繪圖和計算能力、虛擬化以及逼真的 VR 使他們的想像力得以實現。藉由 RTX 技術現在加速的 70 多個世界領先的專業應用程式,專業人士可以更快地設計和構建身臨其境的數位體驗。
NVIDIA RTX A5500 專為要求嚴苛的工作負載而設計,讓專業人士能夠同時運行多個應用程式,使用互動順暢且不會影響效能。NVIDIA RTX A5500 提供構建高品質、身歷其境的內容和隨時隨地協作所需的穩定性、可靠度、效能和功能。NVIDIA RTX A5500 配備 24 GB 的 GPU 記憶體,可通過 NVLink 擴充至 48 GB,可輕鬆處理具有更高解析度和交互性的大型模型、數據集、3D 渲染和複雜場景,幫助用戶從桌面釋放想像力和創造力。
性能特點
NVIDIA Ampere 架構
NVIDIA RTX A5500 是最平衡的工作站 GPU,可在優化的功率範圍內提供高性能的即時光線追踪,AI加速計算和專業圖形渲染。 基於Turing GPU主要增強SM功能,NVIDIA Ampere架構亦強化光線追踪運算,Tensor矩陣運算以及FP32和INT32運算的平行執行。
CUDA 核心
與上一代相比,基於 NVIDIA Ampere 架構的 CUDA 內核帶來高達 3.0 倍的單精度浮點 (FP32) 吞吐量,為繪圖工作流程例如 3D 模型開發和計算模擬等工作負載例如計算機輔助工程(CAE)提供顯著的性能提升 。 RTX A5500啟用兩個FP32主要數據路徑,使FP32峰值運算次數增加了一倍。
第二代 RT核心
結合第二代光線追踪引擎,NVIDIA Ampere GPU架構提供了令人難以置信的光線追踪渲染效能。 單片RTX A5500 卡可以渲染具有物理上準確的陰影,反射和折射的複雜專業模型,從而使用戶能夠立即洞察設計結果。 基於RTX A5500的系統將與利用NVIDIA OptiX,Microsoft DXR和Vulkan光線跟踪等API的應用程式協同工作,將為真正的交互式設計工作流提供強大的動力,以提供即時回饋,從而實現前所未有的生產力水準。 與前一代產品相比,RTX A5500的光線追踪速度提高了2倍。 這項技術還可以加快光線追踪運動模糊的渲染速度,以更快的速度獲得更高的視覺準確性。
第三代 Tensor 核心
RTX A5500專為深度學習矩陣算術而構建,是神經網絡訓練和推理功能的核心,它包括增強的Tensor核心,可加速更多數據類型,並包括新的細粒度結構化稀疏性功能,與上一代相比可為Tensor矩陣提供高達2倍的吞吐量運算。 新的Tensor 核心將加速兩種新的TF32和BFloat16精度模式。獨立的浮點和整數數據路徑可結合使用運算和尋址計算來更有效地執行工作負載。
PCIe 4.0
RTX A5500支援PCI Express Gen 4,該PCI Express Gen 4提供了PCIe Gen 3的兩倍頻寬,進而提高了從CPU 記憶體執行AI和資料科學等數據密集型任務的數據傳輸速度。
更高速的 GDDR6 記憶體
內置 20GB GDDR6 記憶體,可提供記憶體密集型任務(例如光線追踪、渲染和 AI 工作負載)所需的記憶體吞吐量。RTX A5500 提供大容量圖形記憶體,以處理延遲敏感的專業應用程式中的較大數據集和模型。
繪圖記憶體上的錯誤修正碼 (ECC)
符合關鍵性任務應用程式對資料完整性的嚴格需求,為工作站提供無可比擬的計算精確度和可靠性。
第五代NVDEC引擎
NVDEC非常適合用於即時解碼的轉碼和視頻播放應用。 下面視頻編解碼器都支援硬體加速解碼:MPEG-2,VC-1,H.264(AVCHD),H.265(HEVC),VP8,VP9,和AV1。
第七代 NVENC引擎
NVENC可以執行最苛刻的4K或8K視頻編碼任務,以釋放圖形引擎和CPU進行其他運作。 與軟體式的x264編碼器相比,RTX A5500提供更好的編碼品質。
圖形搶佔
像素等級搶佔提供更細微的控制,對時間相關的工作支援更佳,例如 VR 動態追蹤。
計算搶佔
指令等級搶佔提供對計算工作更精細的控制,以避免長時間執行的應用程式獨佔系統資源或超時。
NVIDIA RTX IO
與使用Microsoft新的DirectStorage for Windows API的傳統儲存API相比,基於GPU的無損耗解壓縮性能提高了多達100倍和20倍,且CPU使用率更低。 RTX IO以更有效的壓縮形式將數據從存儲設備移至GPU,並改善了I / O性能。
多 GPU 技術
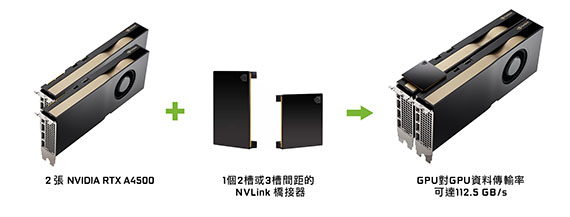
第三代 NVLink
透過以高達112.5 GB / s(總頻寬)的速率實現GPU到GPU的數據傳輸,將兩張RTX A5500卡與NVLink相連,可以有效將記憶體空間增加一倍,並擴展應用程式效能。
NVIDIA® SLI® 技術
利用多個 GPU 動態擴展繪圖效能,加強影像品質,擴大顯示空間,並組裝一套完全虛擬化的系統。
顯示特性
NVIDIA® Quadro® Mosaic 技術
將桌面和應用程式從單一工作站擴展到最多 4 個 GPU 和 16 個顯示器,同時提供完整的效能和影像品質。

DisplayPort 1.4a
支援最多四個 5K 螢幕 @ 60Hz,或每卡兩個 8K 顯示器。RTX A5500 支援 HDR 色彩,包括 4K @ 60Hz 10/12b HEVC 解碼以及高達 4K @ 60Hz 10b HEVC 編碼。 每個 DisplayPort 連接頭可驅動 4096x2160 @ 120 Hz 的超高解析度及 30-bit 色彩。
NVIDIA® RTX™ 桌面管理軟體
終端用戶可獲得前所未有的桌面體驗控制權,從而在單個大型顯示器或多顯示器環境中提高生產率,特別是在當前大型,寬屏顯示器時代。
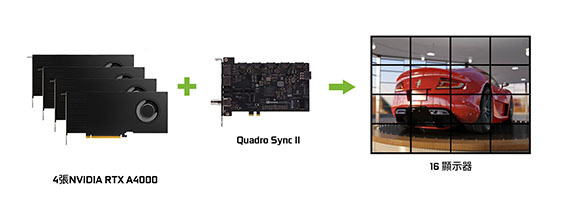
NVIDIA® Quadro Sync II
在單一系統的 8 個 GPU 中同步最多 32 個顯示器的顯示和畫面輸出 (透過兩張 Sync II 介面卡連接),減少建立高階影像可視化環境所需的機器數量。
OpenGL四緩衝立體支援
為專業應用程式提供流暢與身歷其境的 3D 立體體驗。
支援超高解析度桌面
在最大 32K 桌面大小的高解析度顯示器上獲得更多 Mosaic 拓撲選擇。
專業 3D 立體同步
穩定控制立體效果,經由專屬連接直接將 3D 立體硬體同步到 NVIDIA RTX 繪圖卡。
軟體支援
NVIDIA® RTX™ Experience
NVIDIA RTX Experience為您的桌機工作站提供了一套生產力工具,包括高達8K的錄製,針對最新NVIDIA RTX Enterprise驅動程式更新的自動提報以及訪問遊戲功能。
針對 AI 最佳化的軟體
深度學習框架例如 Caffe2, MXNet, CNTK, TensorFlow 等可以大幅加快訓練時間並提高多節點訓練效能。GPU 加速函式庫如 cuDNN, cuBLAS, 和 TensorRT 為深度學習推理和高速計算 (HPC) 應用程式提供更高的效能。
NVIDIA® CUDA® 平行運算平台
原生執行標準程式語言如 C/C++ 和 Fortran,以及 API 如 OpenCL,OpenACC 和 Direct Compute,以加速光線追蹤,影片和影像處理,以及流體力學計算等技術。
單一記憶體
單一無縫的 49 位元虛擬位址空間可讓資料在 CPU 和 GPU 完全分配的記憶體內透明的移動。
NVIDIA® GPUDirect for Video
GPUDirect for Video 經由避免不必要的系統記憶體資料複製和 CPU 負擔來加速 GPU 和影像 I/O 裝置間的溝通。
NVIDIA 企業管理工具
將系統正常運作時間最大化,無縫管理大規模部署並遠端控制圖形和顯示設定,以實現高效率運作。

|














